
ちょっとした技術調査です。
MS Office系のデータとPDFを大量に画像に変換したいことがあったんですが、あまりに量が多くて自動化したくなりました。
「どうせ簡単に出来るやろ」とか余裕ぶっこいてたら実は結構めんどくさかったので、今回はそのやり方をメモとして残しておくものです。
やりたいこと
やりたいことを箇条書きで書くと、
- 対象はパワーポイントとPDF
- エクセルとかワードはページの概念がややこしいので今回は除外
- 出力はJPEG形式
- 一つのファイルからページごとに分割してJPEG形式で保存する
- Dockerコンテナ上で実現したい(linux)
ってところです。最後の一つがなければシンプルです。
方針
流れとしてはこんな感じに思ってます。
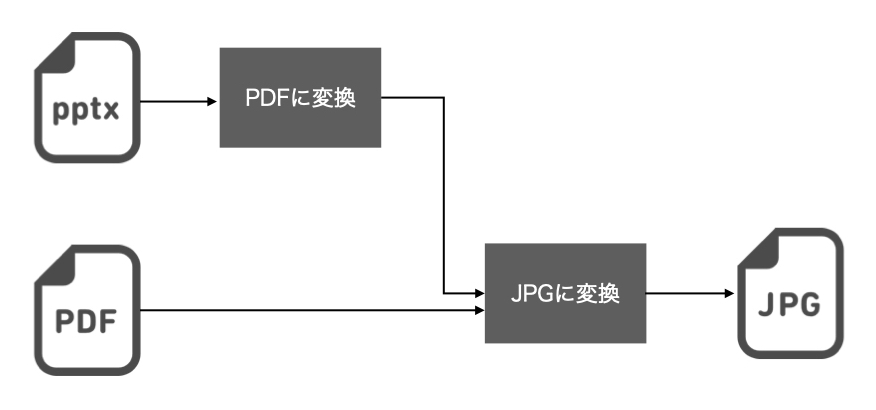
まず、pptxが入力された場合に強引にpdfに変換します。 その後、pdfをjpegへ変換することで最終的に欲しいjpegを取得します。
pptx -> pdf
まず、pptxが入力された場合にLibreOfficeを使って強引にpdfに変換します。 GUIを使えば誰でも出来るのですが、今回は自動化したいのでGUIはなしの方針でやっていきます。
これ意外と厄介で、pptxについては'comtypes'など、windowsで使用するためのライブラリは存在するんですが、windowsのAPIを叩く様になっているようでLinux環境で使用できるライブラリは見当たりませんでした。*1
そのため、pptxについてはpythonライブラリだけではなく、LibreOfficeを使ってやっていくことを考えます。 こちらの記事によれば、LibreOfficeを使えば変換はできそうです。
もろもろ環境を作ってしまえば、下記のようなコマンドで変換はできそうです。
$ libreoffice --headless --nologo --nofirststartwizard --convert-to pdf --outdir <出力先> <変換したいファイル>.pptx
このコマンドを叩くようにしてあげれば、pptx -> pdfの変換はできそうです。
pdf -> jpg
pdfをjpgに変換する際には、'pdf2image'というライブラリを使用したいと思います。 poppler-utilsというツールが必要になるようなので、そちらも合わせてインストールしておきます。
apt install -y poppler-utils
基本的にはこれだけで変換できたりします。
from pathlib import Path
from pdf2image import convert_from_path
pdf_path = Path("hoge.pdf")
img_path=Path("./image")
convert_from_path(pdf_path, output_folder=img_path,fmt='jpeg',output_file=pdf_path.stem)
これでページごとにjpgに変換して出力先フォルダにファイルを置いていってくれます。
やってみる
さて、実際に動くものを作ってみます。 上の方針をベースに、これをファイルを受信して画像を応答するAPIとして作ってみたいと思います。
といっても、Flaskでちゃちゃっと書くだけですが。
from flask import * from werkzeug.utils import secure_filename import os from pathlib import Path from pdf2image import convert_from_path import datetime import subprocess import time import requests DEBUG = True app = Flask(__name__) app.config.from_object(__name__) ALLOWED_EXTENSIONS = {'pdf', 'pptx'} def dirCheck(new_path): if not os.path.exists(new_path): os.mkdir(new_path) def isAllowedFile(filename): return '.' in filename and \ filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS def isPDF(filename): return '.' in filename and filename.rsplit('.', 1)[1].lower() in {'pdf'} def isPPTX(filename): return '.' in filename and filename.rsplit('.', 1)[1].lower() in {'pptx'} dirCheck("/tmp/pptx") dirCheck("/tmp/pdf") #dirCheck("/tmp/jpg") dirCheck("/app/images/jpg") @app.route('/', methods=['POST']) def index(): # atatched somthing? if 'file' not in request.files: return "no file\n" file = request.files['file'] # atatched file? if file.filename == '': return 'No selected file\n' if not isAllowedFile(file.filename): return 'no allowed files\n' filename = secure_filename(file.filename) now = datetime.datetime.now() dtstr = now.strftime('%Y%m%d%H%M%S') # => '2019-08-02T02:20:43' dir_name = filename.split('.')[0] + "_" + dtstr if isPPTX(file.filename): output_path = os.path.join("/tmp/pptx", dir_name) dirCheck(output_path) file.save(os.path.join("/tmp/pptx", dir_name, filename)) # pptx -> pdf output_path = os.path.join("/tmp/pdf", dir_name) dirCheck(output_path) res = subprocess.call(['libreoffice', '--headless', ' --nologo', '--nofirststartwizard', '--convert-to', 'pdf', '--outdir', output_path, os.path.join("/tmp/pptx", dir_name, filename)]) # pdf -> jpg (recursive request) file = {'file': open(os.path.join("/tmp/pdf", dir_name, filename.split('.')[0] + '.pdf'), 'rb')} return requests.post('http://localhost:5000/', files=file).text elif isPDF(file.filename): output_path = os.path.join("/tmp/pdf", dir_name) dirCheck(output_path) file.save(os.path.join(output_path, filename)) pdf_path = Path(os.path.join(output_path, filename)) #output_path = os.path.join("/tmp/jpg", dir_name) output_path = os.path.join("/app/images/jpg", dir_name) dirCheck(output_path) convert_from_path(pdf_path, output_folder=output_path,fmt='jpeg',output_file=pdf_path.stem) return output_path if __name__ == '__main__': app.run()
特にpptxとpdfのファイルを拡張子で見分け、それぞれで変換をします。 pptxを受信した場合については、pdfに変換するために、自分自身にもう一度post requestを送信するようになっています。
うまく変換ができれば、imagesディレクトリの中に画像が保存されるはずなので、後はAPIを追加してファイル自体を応答したり、ファイルの一覧を返したりする部分を作ってあげれば問題なさそうです。
作ったもの
作ったものはこちら。
参考文献
感想
やり方がよくわかんなかったので、メモ書きとして残した次第です。 せっかくのGWになにやってんだか…
こんなことやりたくなる人はそんなにいないとは思いますが、単なるメモ書きでした。今回はこのへんで。